What is Datasette
Datasette is a tool for exploring and publishing data. It is used for creating and publishing JSON APIs for SQLite databases.
Datasette makes it easy to expose JSON APIs from our SQLite database without the need of a custom web application.
It helps people take data of any shape or size and publish that as an interactive, explorable website and accompanying API. Datasette is aimed at data journalists, archivists, local governments and anyone else who has data that they wish to share with the world.
Installation
We can install Datasette using docker or pip. Let us install using pip(datasette requires min python3.5)
$ pip install datasette
To use datasette on any SQLite db just run
$ datasette serve some-sqlite-database.db
this command serves up specified SQLite database files with a web UI
For sample datasets - https://github.com/simonw/datasette/wiki/Datasettes
Let us take a sample data from fivethirtyeight data repo as it has wide range of datasets.
let us use comic-characters data in the repo, and let us explore the dc-wikia-data.csv
first let us install a package to convert the csvs to sqlite db
$ pip install csvs-to-sqlite
now let us convert the csv to sqlite db
$ csvs-to-sqlite dc-wikia-data.csv dc-wikia-data.db
Now let us serve the sqlite db
$ datasette serve dc-wikia-data.db
Serve! files=('dc-wikia-data.db',) (immutables=()) on port 8001
INFO: Started server process [12668]
INFO: Waiting for application startup.
INFO: Uvicorn running on http://127.0.0.1:8001 (Press CTRL+C to quit)
Now when we go to the url
we can see that there are 6000+ rows in the table,
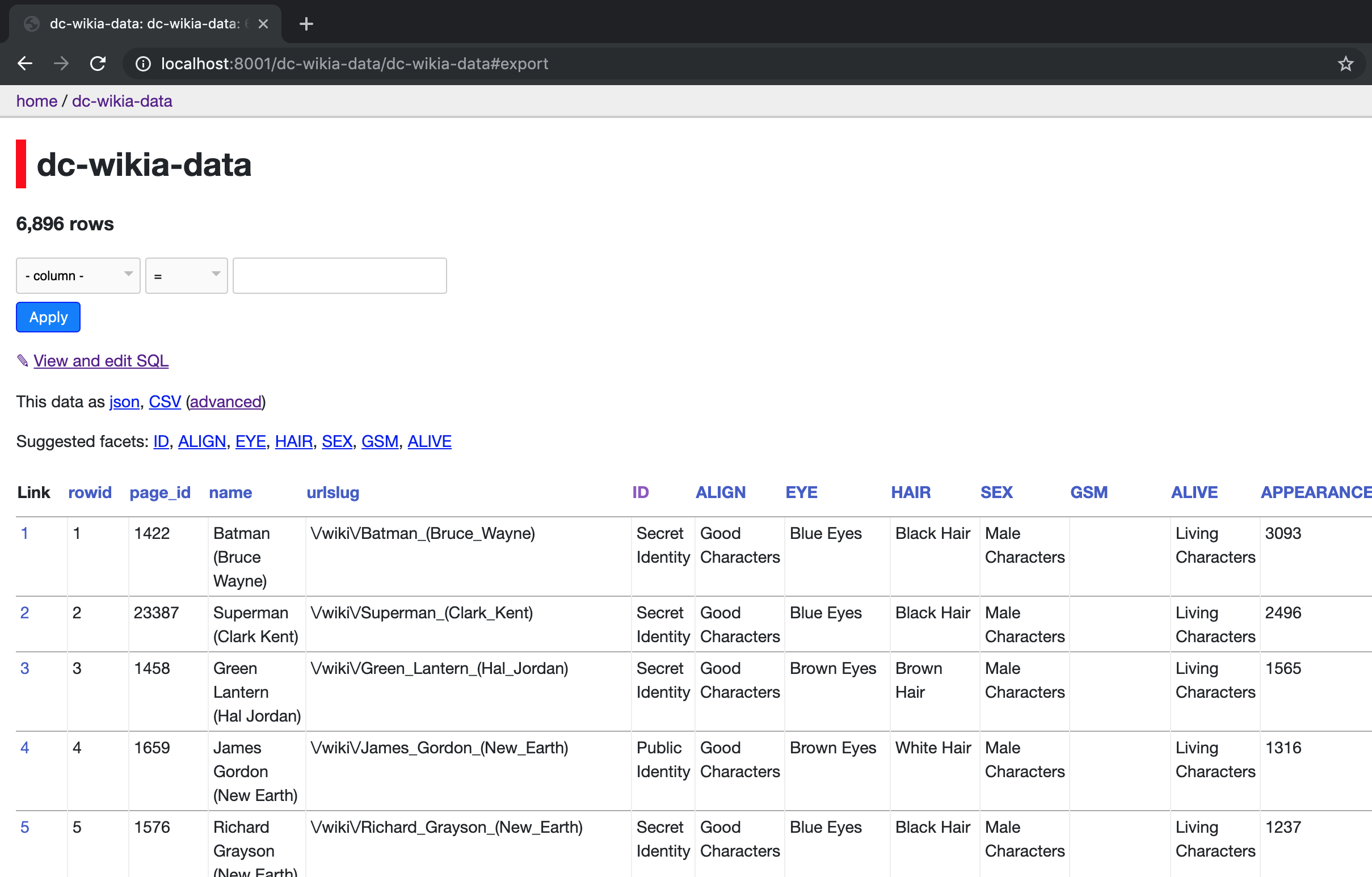
let’s click on the table name
this will take us to the page where we can view/filter the table and also edit the sql queries
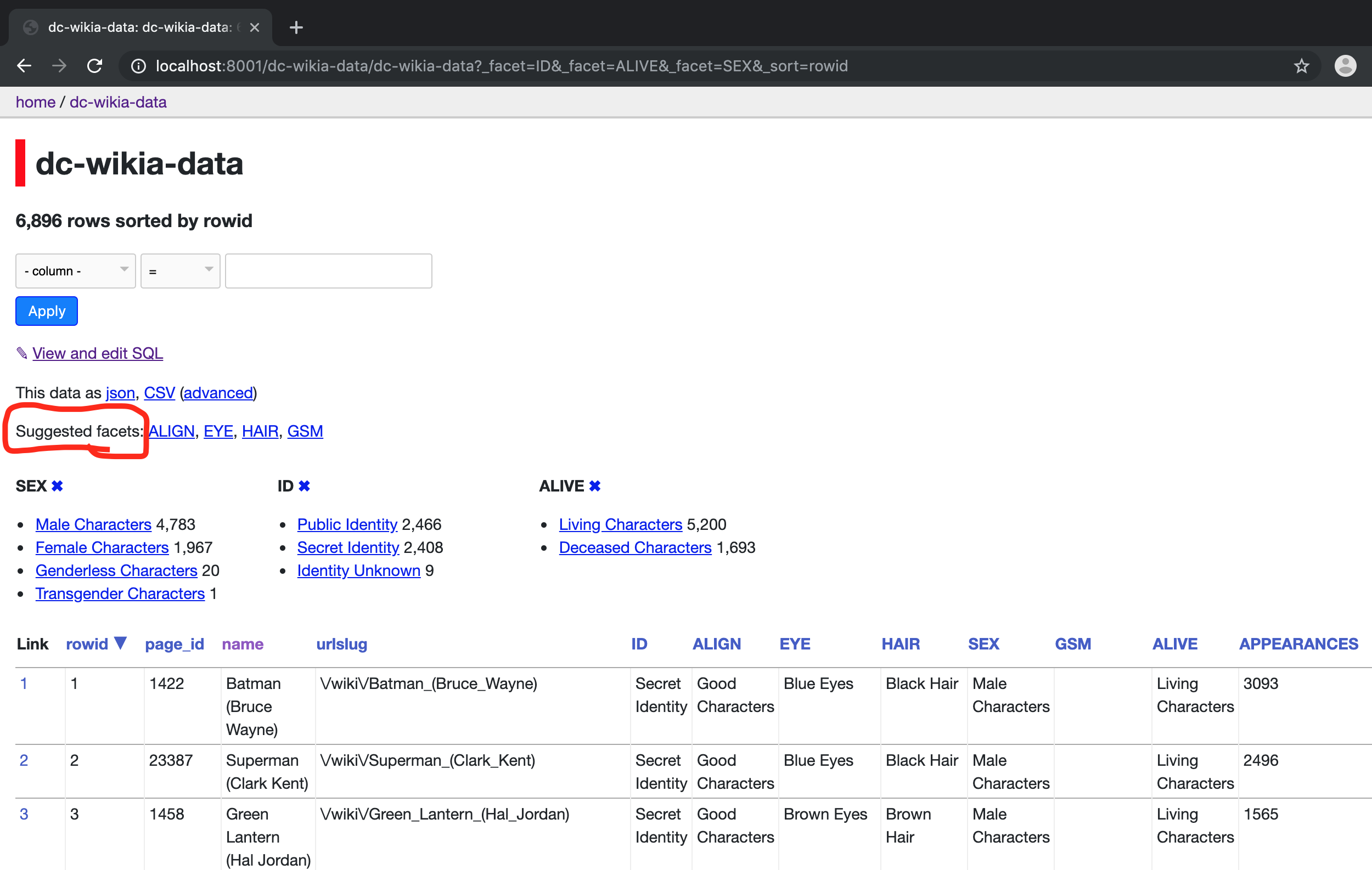
Now let us filter the table by clicking on the suggested facets like -
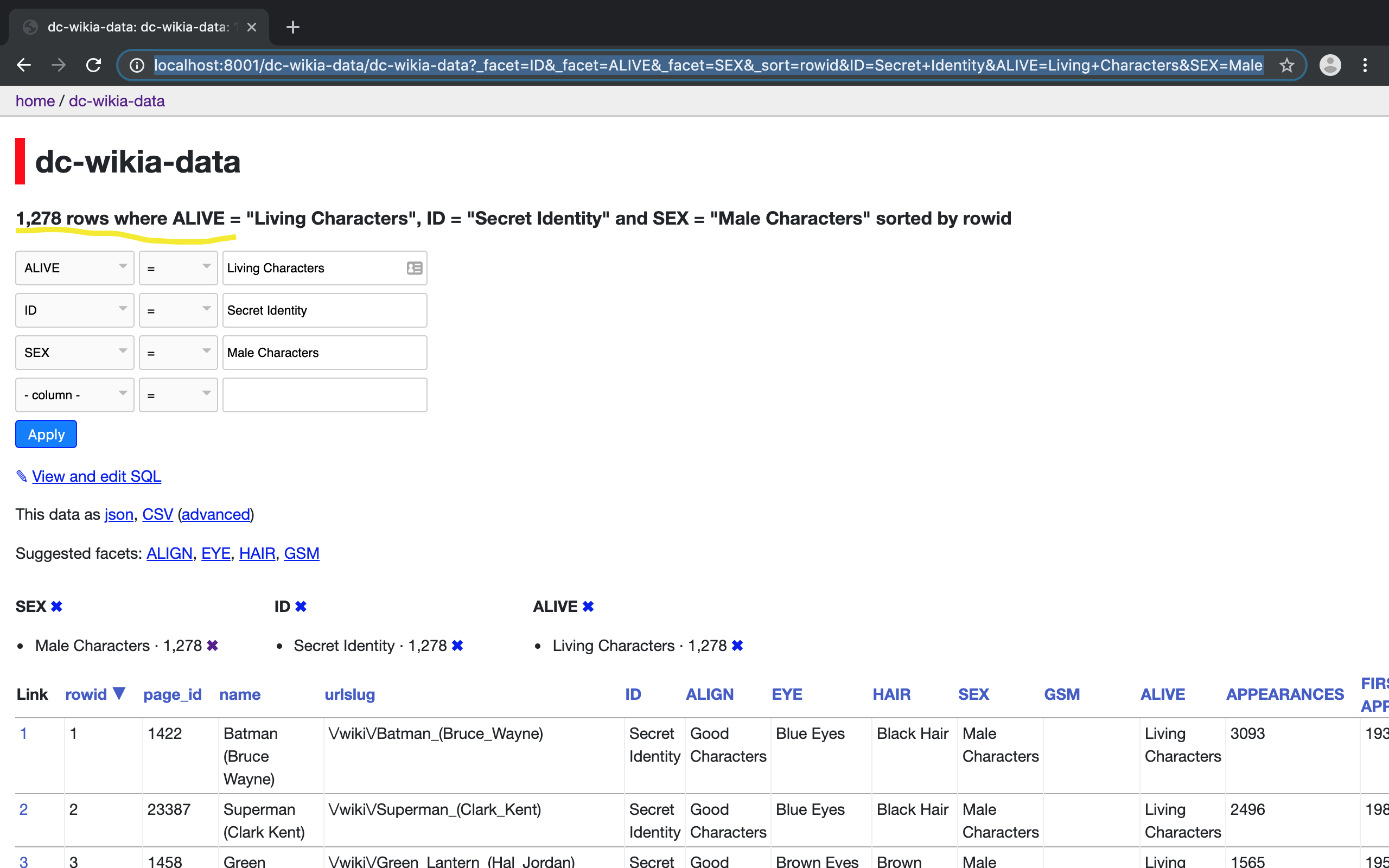
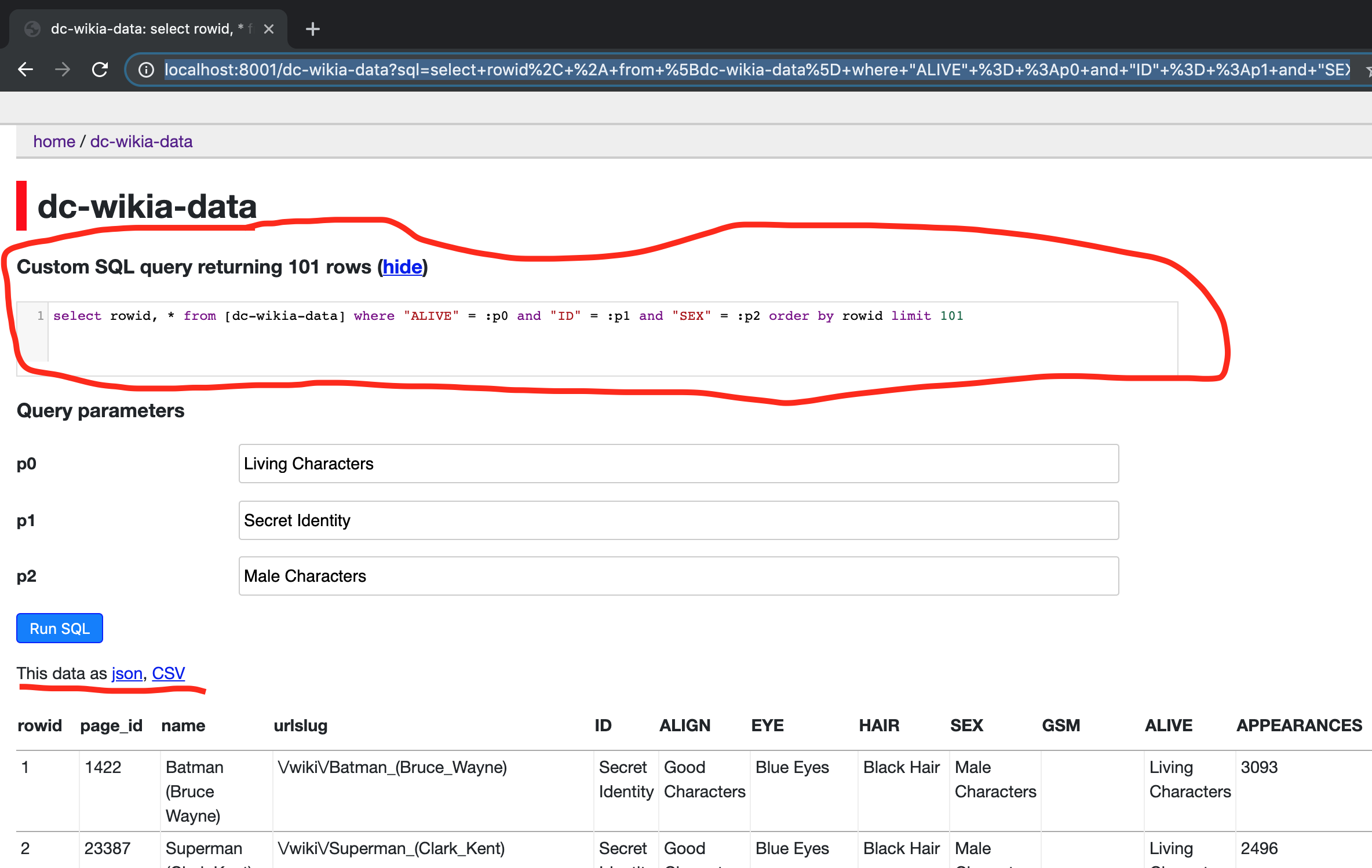
We can also view the filtered-data in json or csv and also download the filtered data
Everything datasette can do is driven by URLs. Queries can produce responsive HTML pages or with the .json or .jsono extension can produce JSON. All JSON responses are served with an Access-Control-Allow-Origin: * HTTP header, meaning we can query them from any page.
we can view the data in the browser by accessing the link
http://localhost:8001/dc-wikia-data?sql=select+*+from+%5Bdc-wikia-data%5D
and we can get the json for the same data by
http://localhost:8001/dc-wikia-data.json?sql=select+*+from+%5Bdc-wikia-data%5D
Or we can get the csv for the same data by
http://localhost:8001/dc-wikia-data.csv?sql=select+*+from+%5Bdc-wikia-data%5D
Datasette serving options
$ datasette serve --help
Usage: datasette serve [OPTIONS] [FILES]...
Serve up specified SQLite database files with a web UI
Options:
-i, --immutable PATH Database files to open in immutable mode
-h, --host TEXT host for server, defaults to 127.0.0.1
-p, --port INTEGER port for server, defaults to 8001
--debug Enable debug mode - useful for development
--reload Automatically reload if database or code change detected -
useful for development
--cors Enable CORS by serving Access-Control-Allow-Origin: *
--load-extension PATH Path to a SQLite extension to load
--inspect-file TEXT Path to JSON file created using "datasette inspect"
-m, --metadata FILENAME Path to JSON file containing license/source metadata
--template-dir DIRECTORY Path to directory containing custom templates
--plugins-dir DIRECTORY Path to directory containing custom plugins
--static STATIC MOUNT mountpoint:path-to-directory for serving static files
--memory Make :memory: database available
--config CONFIG Set config option using configname:value
datasette.readthedocs.io/en/latest/config.html
--version-note TEXT Additional note to show on /-/versions
--help-config Show available config options
--help Show this message and exit.
Converting data to SQLite DB
To view the data using we have to convert the initial data to SQLite database, and we can convert it by using python packages
-
for CSV -
csvs-to-sqlitelets us take one or more CSV files and load them into a SQLite database. -
for databases -
db-to-sqliteis a CLI tool that builds on top of SQLAlchemy and allows us to connect to any database supported by that library (including MySQL, oracle and PostgreSQL), run a SQL query and save the results to a new table in a SQLite database. -
Using Programmatically -
sqlite-utilsis a Python library and CLI tool that provides shortcuts for loading data into SQLite. It can be used programmatically (e.g. in a Jupyter notebook) to load data, and will automatically create SQLite tables with the necessary schema.
Datasette Plugins
Datasette’s plugin system allows additional features to be implemented as Python code (or front-end JavaScript) which are wrapped up as a separate Python package.
-
datasette-vega -
datasette-vegaallows us to construct line, bar and scatter charts against our data and share links to our visualizations. It is built using the Vega charting library, -
datasette-cluster-map -
datasette-cluster-mapThe plugin works against any table with latitude and longitude columns. It can load over 100,000 points onto a map to visualize the geographical distribution of the underlying data. -
datasette-cors -
datasette-corsthis plugin allows JavaScript running on a whitelisted set of domains to make fetch() calls to the JSON API provided by our Datasette instance.
Let us check datasette-vega plugin in our dataset
$ pip install datasette-vega
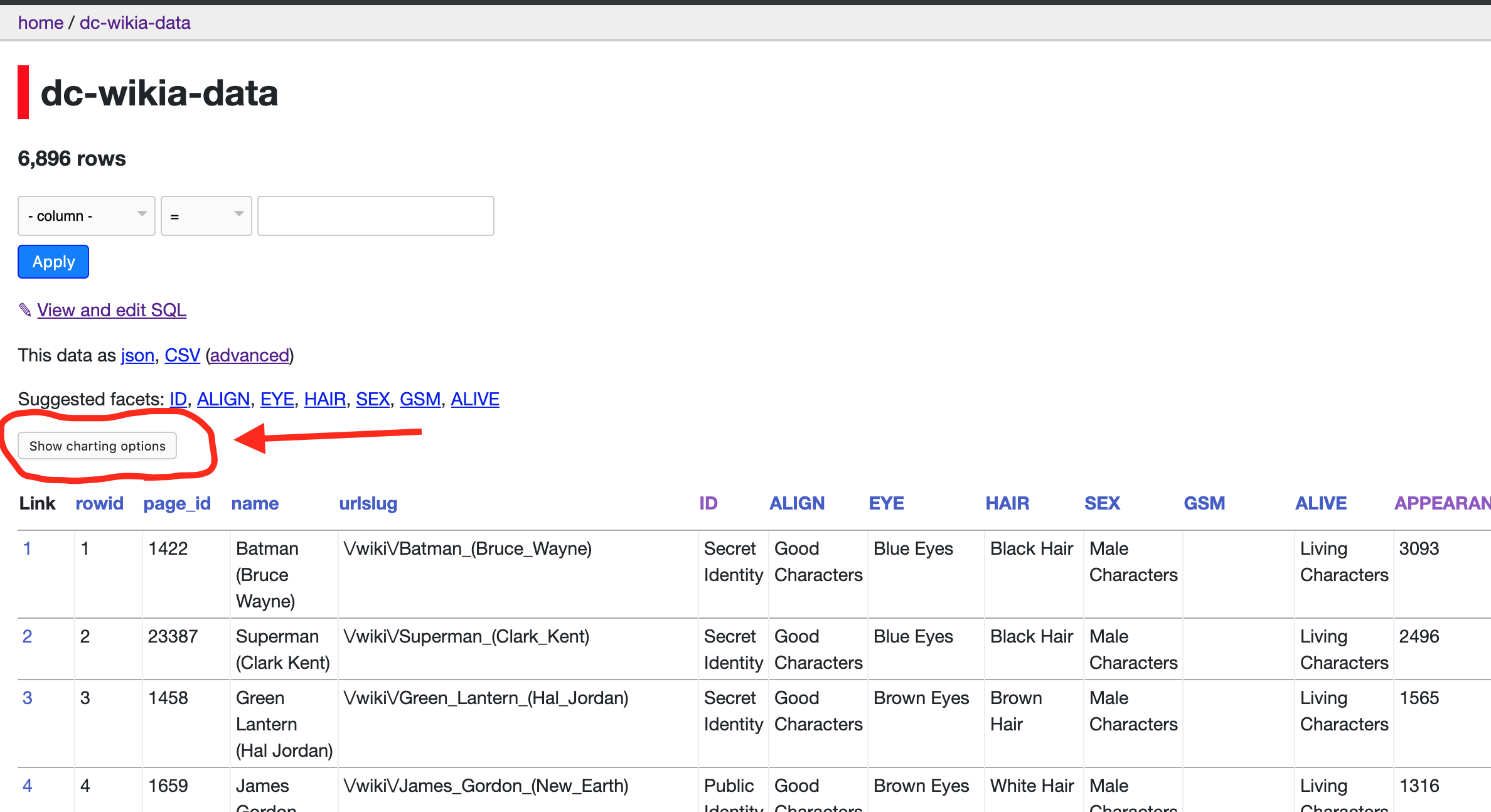
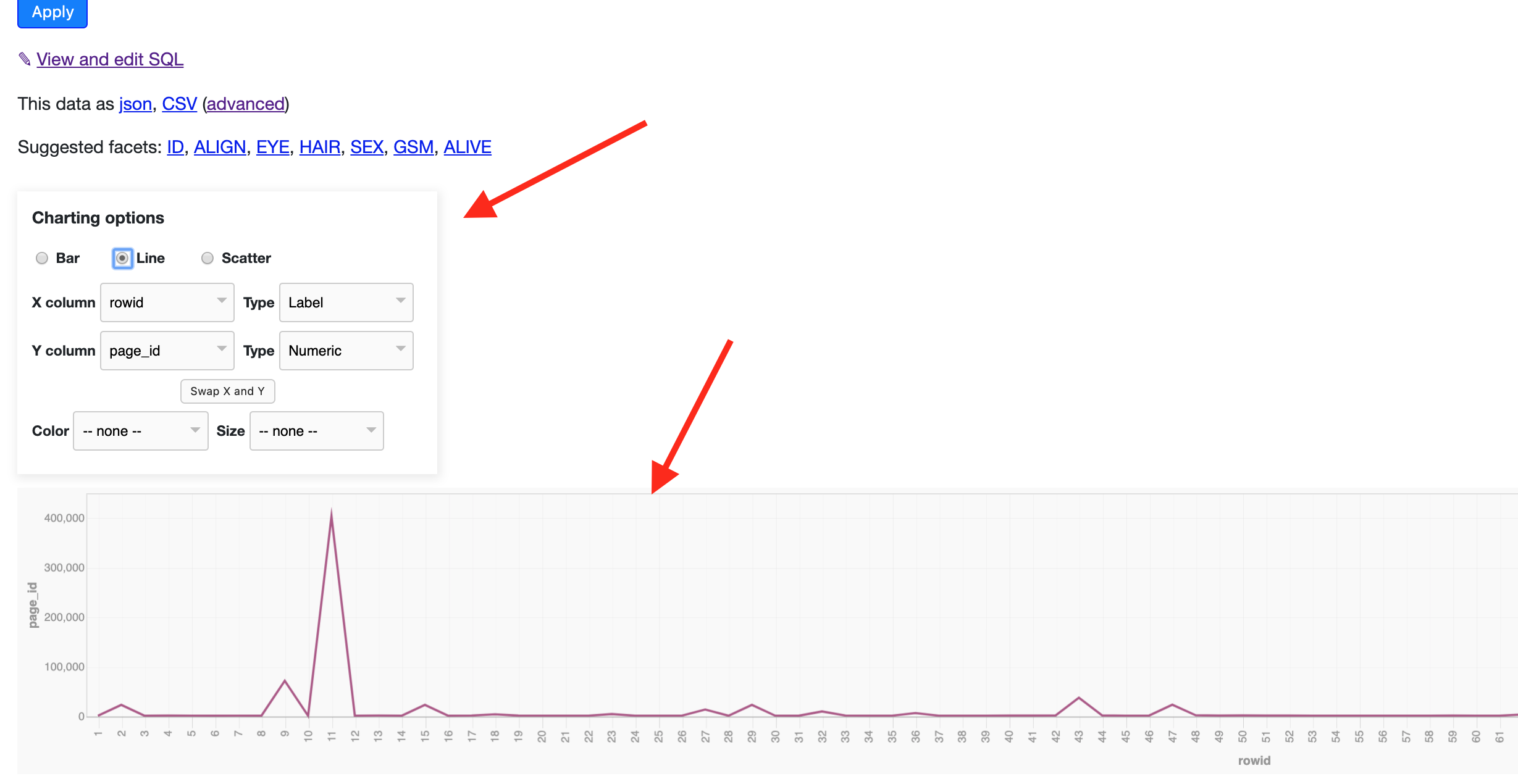
Using this plugin we get the charting options like bar, line and scatter.
Pages and API endpoints
The Datasette web application offers a number of different pages that can be accessed to explore the data, each of which is accompanied by an equivalent JSON API.
The allow_sql config option is enabled by default, which enables an interface for executing arbitrary SQL select queries against the data.
Every row in every Datasette table has its own URL. This means individual records can be linked to directly.
We can return the JSON/CSV data by appending .json/.csv to the URL path, before any ? querystring arguments.
Publishing data
Datasette has tools for publishing and deploying our data to the internet.
The datasette publish command will deploy a new Datasette instance containing our databases directly to a Heroku or Google Cloud hosting account.
We can also use datasette package to create a Docker image that bundles our databases together with the datasette application that is used to serve them.
Running SQL queries
Datasette treats SQLite database files as read-only and immutable.
This means it is not possible to execute INSERT or UPDATE statements using Datasette, which allows us to expose SELECT statements to the outside world without needing to worry about SQL injection attacks.
The easiest way to execute custom SQL against Datasette is through the web UI.
Any Datasette SQL query is reflected in the URL of the page, allowing us to bookmark them, share them with others and navigate through previous queries using our browser back button.
Datasette supports many features like -
-
Named parameters - Datasette has special support for SQLite named parameters.
-
Pagination - When paginating through tables, Datasette instead orders the rows in the table by their primary key and performs a WHERE clause against the last seen primary key for the previous page.
For example:
select rowid, * from [dc-wikia-data] where rowid > 200 order by rowid limit 101
JSON/CSV Export
Any Datasette table, view or custom SQL query can be exported as JSON/CSV.
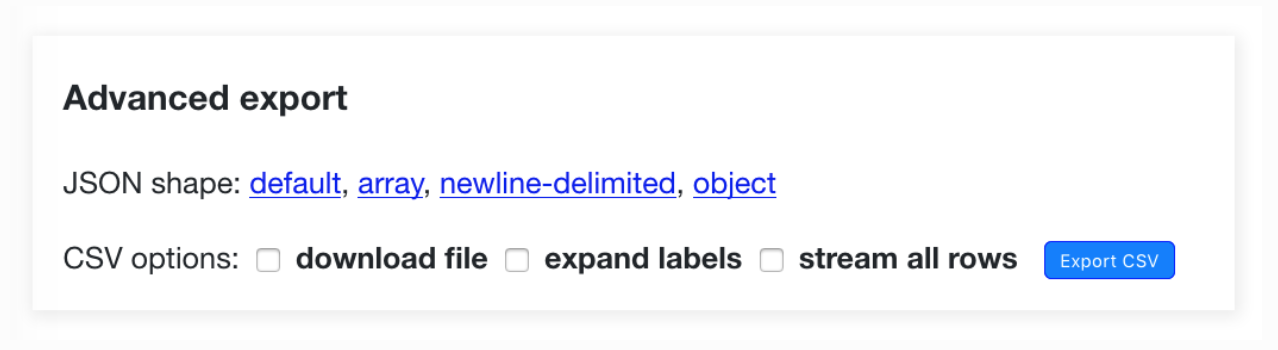
- download file - instead of displaying CSV in your browser, this forces your browser to download the CSV to your downloads directory.
- expand labels - if your table has any foreign key references this option will cause the CSV to gain additional
COLUMN_NAME_labelcolumns with a label for each foreign key derived from the linked table. - stream all rows - by default CSV files only contain the first
max_returned_rowsrecords. This option will cause Datasette to loop through every matching record and return them as a single CSV file.
The default URL for the CSV representation of a table is that table with .csv appended to it:
- https://latest.datasette.io/fixtures/facetable - HTML interface
- https://latest.datasette.io/fixtures/facetable.csv - CSV export
- https://latest.datasette.io/fixtures/facetable.json - JSON API
Full-text search
SQLite includes a powerful mechanism for enabling full-text search against SQLite records. Datasette can detect if a table has had full-text search configured for it in the underlying database and display a search interface for filtering that table.
Datasette automatically detects which tables have been configured for full-text search.
Adding full-text search to a SQLite table
Datasette takes advantage of the external content mechanism in SQLite, which allows a full-text search virtual table to be associated with the contents of another SQLite table.
To set up full-text search for a table, we need to do two things:
- Create a new FTS virtual table associated with our table
- Populate that FTS table with the data that we would like to be able to run searches against
Configuration
Datasette provides a number of configuration options. These can be set using the --config name:value option to datasette serve.
We can set multiple configuration options at once like
$ datasette dc-wikia-data.db --config default_page_size:50 \
--config sql_time_limit_ms:3500 \
--config max_returned_rows:2000
among many config options, the most frequently used are:
default_page_size- The default number of rows returned by the table page. We can over-ride this on a per-page basis using the?_size=80querystring parameter, provided we do not specify a value higher than themax_returned_rowssetting. We can set this default using--configlike so:
$ datasette dc-wikia-data.db --config default_page_size:50
max_returned_rows- Datasette returns a maximum of 1,000 rows of data at a time. You can increase or decrease this limit like so:
$ datasette dc-wikia-data.db --config max_returned_rows:2000
Customization
Datasette provides a number of ways of customizing the way data is displayed. Like
- Custom CSS and JavaScript - we can specify a custom metadata file like this:
$ datasette dc-wikia-data.db --metadata metadata.json
And in metadata.json file can include links like this:
{
"extra_css_urls": [
"https://simonwillison.net/static/css/all.bf8cd891642c.css"
],
"extra_js_urls": [
"https://code.jquery.com/jquery-3.2.1.slim.min.js"
]
}
The extra CSS and JavaScript files will be linked in the <head> of every page.
- Custom templates - We can over-ride the default templates by specifying a custom
--template-dirlike this:
$ datasette dc-wikia-data.db --template-dir=mytemplates/
Thank you for reading the Agiliq blog. This article was written by Anmol Akhilesh on Jul 12, 2019 in datasette , sqlite , python , api .
You can subscribe ⚛ to our blog.
We love building amazing apps for web and mobile for our clients. If you are looking for development help, contact us today ✉.
Would you like to download 10+ free Django and Python books? Get them here
